ATAC-seq data analysis
 Johnny发布于 July 22,2024
Johnny发布于 July 22,2024
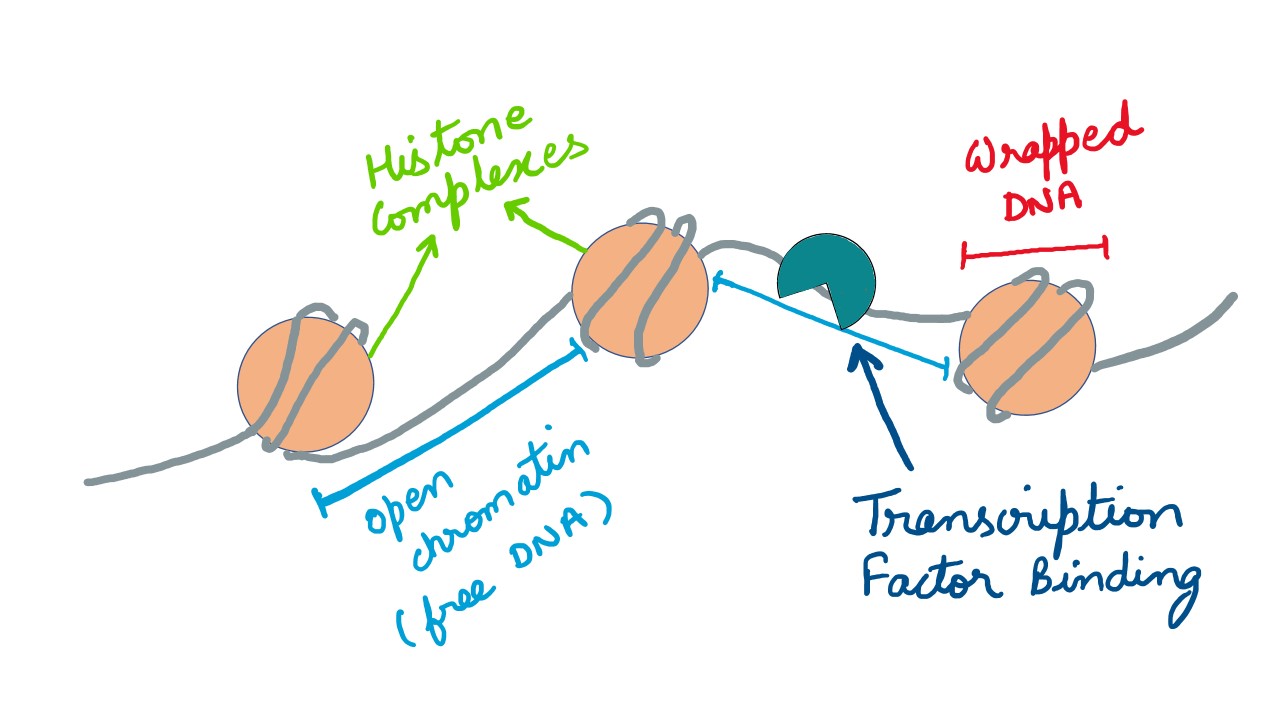 Johnny发布于 July 22,2024
Johnny发布于 July 22,2024
 Johnny发布于 July 19,2024
Johnny发布于 July 19,2024
 Johnny发布于 July 11,2024
Johnny发布于 July 11,2024
 Johnny发布于 July 11,2024
Johnny发布于 July 11,2024
 Johnny发布于 June 21,2024
Johnny发布于 June 21,2024
 Johnny发布于 June 21,2024
Johnny发布于 June 21,2024
 Johnny发布于 June 08,2024
Johnny发布于 May 06,2024
Johnny发布于 June 08,2024
Johnny发布于 May 06,2024
 Johnny发布于 May 06,2024
Johnny发布于 May 06,2024
 Johnny发布于 May 03,2024
Johnny发布于 April 30,2024
Johnny发布于 May 03,2024
Johnny发布于 April 30,2024
